La belle affaire, pas de quoi fouetter un ChatGPT…
Après plus de deux ans d’attente [1] d’enflure médiatique, de promesses d’IA générale (en anglais AGI) et même de « superintelligence », le récent GPT-5 est un pétard mouillé. Ce qui explique probablement sa sortie au cœur de l’été, le 7 août 2025.
Pourtant les attentes étaient grandes et tout à fait à la hauteur des promesses délirantes. Rappelons-nous le 21 mai 2024 à la journée Microsoft Build 2024 [2], Kevin Scott le chef des technologies de Microsoft en compagnie de Sam Altman d’OpenAI affirmait « We are nowhere near the point of diminishing marginal returns on how powerful we can make AI models as we increase the scale of compute » [3] avec en toile de fond une courbe exponentielle de progression du modèle GPT. Plus tard, Kevin Scott comparait la taille de l’infrastructure de calcul pour GPT-5 à une baleine bleue, alors qu’il suffisait d’un épaulard pour entraîner GPT-4 et d’un requin blanc pour GPT-3. Et pour ne pas être en reste, Sam Altman affirmait : « As the models get more powerful there will be many new things to figure out as we move towards AGI. » [4].
Sans oublier les nombreuses déclarations de Sam Altman quand il affirmait que l’amélioration de GPT-4 à GPT-5 sera aussi important que celui de GPT-3 à GPT-4: « GPT-4 to GPT-5 will be a similar leap, and it’s amazing! » [5] ou encore cette autre [6] où il suggérait que les modèles d’OpenAI allaient continuer à s’améliorer pendant « trois ou quatre » générations supplémentaires. Enfin, les prévisions dithyrambiques à saveur religieuse de Sam Altman sur son blogue: « Humanity is close to building digital superintelligence » [7].
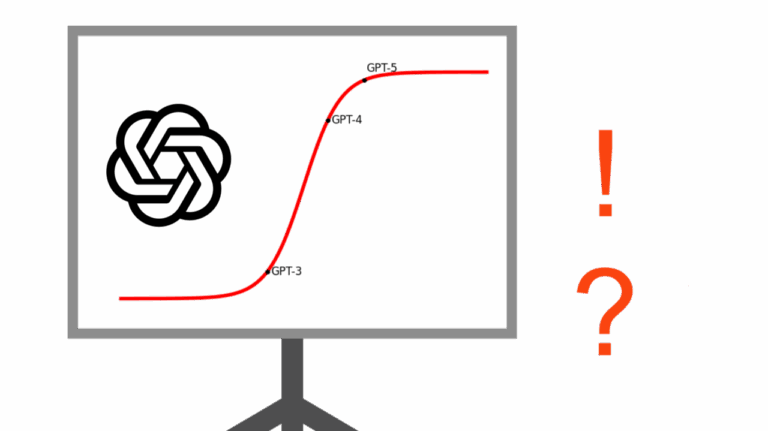
La courbe d’évolution exponentielle est plutôt une sigmoïde
L’hypothèse quasi religieuse d’une « intelligence artificielle » croissante avec la montée en échelle (c.-à-d. plus de données et plus de calculs) a frappé un mur! Pour les grands modèles de langues ou GML (en anglais LLM), plus gros et plus grands ne signifient pas plus intelligents. La courbe d’évolution des GML ne serait pas l’exponentielle rêvée mais plutôt une sigmoïde bien connue des praticiens des réseaux neuronaux.
Ici je m’amuse un peu, la forme réelle de cette courbe évolutive des GML est difficile à prédire. Ce que nous savons est que la courbe a démarré comme une exponentielle et qu’elle donne des signes évident de ralentissement, voire de plafonnement ou de plateau, d’où mon hypothèse d’une sigmoïde. Les points et la forme de la courbe de l’image dans l’entête de cet article sont une illustration purement caricaturale.
« Le plus important à retenir de GPT-5 est que les grands modèles de langues plafonnent. » – Claude Coulombe
Une chose est sûre, les progrès de GPT-5 sur GPT-4 ne sont pas comparables aux progrès de performance des modèles précédents de la famille GPT, comme les améliorations entre le GPT-3 en 2020 et le GPT-4 en 2023.
Mes constatations rejoignent celles de Gary Marcus, expert en IA et sceptique notoire de l’approche des grands modèles de langues pour atteindre l’IA générale [8]. Dans le même ordre d’idées, je recommande la vidéo de la physicienne et vulgarisatrice scientifique Sabine Hossenfelder intitulée « GPT-5: Have We Finally Hit the AI Scaling Wall? » [9].
« Nobody with intellectual integrity should still believe that pure scaling will get us to AGI » – Gary Marcus [10]
Il est surprenant de constater ce que les grands modèles de langues ont réussi à accomplir grâce aux propriétés des espaces sémantiques latents multidimensionnels, le mécanisme d’attention (merci aux travaux pionniers de Yoshua Bengio) et quelques astuces comme la bonne vieille recherche arborescente améliorée avec Monte-Carlo.
Les GML ne raisonnent pas, ils font semblant
Une première étude scientifique émanant du groupe de recherche en IA d’Apple Intitulée « The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity » [11] remettait en question l’idée selon laquelle les GML pouvait raisonner en généralisant à n’importe quel niveau de profondeur et montrait qu’ils échouaient sur des versions modérément complexes d’algorithmes de base comme la Tour de Hanoi. Au-delà d’un certain niveau de complexité des problèmes, les GML n’arrivent pas à suivre les règles logiques de base nécessaires. Ceci jette un sérieux doute sur la capacité des GML à généraliser et assurément à atteindre un jour l’AGI.
Un étude récente « Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens» [12] de chercheurs de l’Arizona State University montre que la chaîne de résolution (en anglais, Chain of Thought) [13], la prétendue trace du raisonnement qui provient des robots conversationnels génératifs (RCG) basés sur des GML, n’est qu’un « mirage fragile ». Les RCG ne raisonnent pas. Ils effectuent une recherche de formes dans leurs espace latent créé à partir de leurs données d’entraînement. Les chercheurs ont demandé aux modèles de résoudre des énigmes logiques nécessitant une généralisation « hors distribution ». Dès qu’un problème s’écarte, même légèrement, de ses données d’entraînement, le « pseudo raisonnement » s’effondre complètement.
Aussi, des chercheurs d’Anthropic, l’entreprise derrière le robot conversationnel génératif Claude ont découvert que les étapes de la chaîne de résolution (en anglais, Chain of Thought) utilisées par les modèles ne correspondent pas vraiment au résultat [14]. Autrement dit, le modèle peut avoir des étapes de résolution de problèmes correctes mais aboutir à un résultat erroné, ou obtenir un résultat correct à partir d’étapes erronées. Leur recherche suggère que les GML ne sont pas des moteurs de raisonnement complet, mais plutôt des simulateurs / générateurs sophistiqués de textes de raisonnement. Plutôt que de démontrer une véritable compréhension du problème, la chaîne de résolution applique des schémas appris pendant l’entraînement.
Les fabulations (mal-nommées hallucinations) ne sont toujours pas résolues
Une chose est sûre, le problème des fabulations perdure, et n’est toujours pas réglé depuis bientôt trois ans et bien des promesses. En quelques jours seulement depuis la sortie de GPT-5, la Toile déborde d’erreurs commises par GPT-5, des erreurs du même type que celles de ses prédécesseurs.
Ce modèle soi-disant de niveau « expert avec Ph. D. » d’après Sam Altman, n’est toujours pas capable de compter avec fiabilité le nombre de lettres « R » dans le nom d’un fruit ou de réaliser des opérations arithmétiques élémentaires.
En y réfléchissant, une partie de ces problèmes pourrait provenir du nouveau module d’aiguillage (en anglais, model switcher) qui choisit le modèle approprié. Par exemple, GPT-5 faisait le choix d’un interpréteur Python lorsque vous saisissez les mots « calculer », « ajouter » ou « soustraire », mais pas quand vous tapiez directement une expression mathématique. Le problème du choix de modèle semblait également lié au type d’abonnement: gratuit, payant ou cher. Des amis m’ont dit que les versions payantes étaient exemptes de ces erreurs triviales. Par contre, le comportement erratique du module de commutation au lancement de GPT-5 en dit long sur le contrôle de qualité d’OpenAI. Cela ressemble à du travail d’amateur ou de stagiaire.
Cela dit, d’autres erreurs du même genre et des fabulations sont découvertes chaque jour en utilisant GPT-5.
Dire que certains voudraient confier à des GML puissants mais peu fiables, nos économies, nos tribunaux, notre sécurité et même nos vies dans des applications médicales. Je l’enseigne et je le répète, pour les « applications critiques » l’humain doit demeurer dans la boucle. En vertu de la nature même des systèmes basés sur des GML, on ne peut pas garantir leur fiabilité à cause des fabulations que l’on peut réduire en utilisant des techniques comme la génération augmentée d’information applicative (GAIA, en anglais RAG) mais jamais totalement éliminer.
Un article intitulé « The wall confronting large language models » [15] est paru quelques semaines avant le lancement de GPT-5. Cet article révise les lois de mise à l’échelle des grands modèles de langues. Ces lois ne prendraient pas en compte le fait que l’élimination des erreurs nécessite une quantité extrêmement importante de calculs. Selon l’étude, réduire le taux d’erreur des GML actuels pour les rendre fiables pour une utilisation en entreprise, nécessiterait une puissance de calcul 1.0 E+20 fois supérieure (c.-à-d. 10 exposant 20). C’est matériellement impossible.
Je demeure curieux de connaître un estimation honnête du pourcentage de réduction des fabulations de GPT-5 par rapport à GPT-4.
De plus, ces modèles sont des boîtes noires incapables d’expliquer leurs décisions. Pour les « questions de vie ou de mort », l’humain doit demeurer dans la boucle et assumer la responsabilité des décisions.
Enfin, je ne fais que mentionner au passage les risques d’addiction, d’aggravation des troubles mentaux et de perte cognitive associés à l’usage abusifs des robots conversationnels génératifs. Le développement et le maintien de capacités cognitives complexes nécessitent un travail actif et ne peuvent reposer uniquement sur l’assistance technologique. En ce qui concerne les réseaux neuronaux naturels, c’est « utilisez-les ou perdez-les » [16].
GPT-5, un échec prévisible
Selon le magazine The Information de la Silicon Valley [17], sur la base d’informations obtenues de sources internes à OpenAI et son partenaire Microsoft à l’automne 2024, Orion qui était le nom de code pour GPT-5 est une grande déception. Il représentait un saut qualitatif nettement moins important que le passage de GPT-3 à GPT-4. OpenAI décide alors de le lancer sous le nom de GPT-4.5 car il ne représentait pas une avancée suffisante.
Les GML, de par leur objectif (prédire le mot suivant en fonction du contexte) et surtout de leur dépendance sur les données d’entraînement, étaient probablement destinés à atteindre un plateau. Les parties prenantes et trébuchante$, OpenAI et Microsoft et d’autres techno-optimistes entretenaient le mythe de l’émergence de propriétés spectaculaires et d’une quantité illimitée de données d’entraînement quitte à les synthétiser. Pour ma part, côté « propriétés émergentes », je n’ai observé qu’une meilleure capacité à réaliser des tâches plus variées sans aucun exemple (en anglais, zero-shot) ou avec très peu d’exemples (en anglais, few-shot).
Il n’est pas surprenant de constater que les grands modèles génératifs sont bons dans trois domaines où l’on retrouve de grands gisements de données sur la Toile: les textes incluant l’audio, les images incluant la vidéo et le code de programmation.
Un problème majeur est la raréfaction des données de haute qualité pour entraîner les GML. Une fois écumé la Toile et les livres numériques [18], l’apport de textes fournis par les travailleurs du clic, mal payés bien que plusieurs soient détenteurs de Ph.D. n’arrive qu’à combler les lacunes les plus importantes en mathématiques, en résolution de problèmes et en programmation. C’est ce que j’ai appelé, l’amélioration des GML par la technique « bouche-trou », qui consiste à améliorer les résultats dans les bancs d’essai en comblant les trous. Pas évident de se rendre à l’AGI avec cette méthode!
Pour atténuer le problème du manque de données, il est probable que l’équipe d’OpenAI ait utilisé beaucoup de données synthétiques pour le pré-entraînement de GPT-5. Puis peaufiné en post-entraînement avec beaucoup d’apprentissage par renforcement.
GPT-5 plus rapide, plus savant et meilleur en programmation
GPT-5 n’est pas la révolution annoncée, tout au plus une bonne évolution au prix de dépenses en argent, en énergie, en GES émis et en ressources sans égal. GPT-5 est certes plus rapide (merci aux puces plus puissantes et aux optimisations), meilleur sur les bancs d’essai habituels dont beaucoup de réponses se retrouvent probablement dans le jeu d’entraînement du modèle [19], meilleur en programmation comme la plupart des modèles concurrents (et nous verrons plus loin pourquoi) et avec une réduction annoncée des fabulations (les mal nommées hallucinations) qui reste à prouver. Enfin, une diminution du prix, ce qui n’est pas un bon signe pour un produit amélioré et révolutionnaire.
Disons-le, la seule véritable application-phare des robots conversationnels génératifs est la tricherie étudiante, comme l’illustre bien la courbe d’utilisation de ChatGPT qui suit l’activité des sessions étudiantes. Mais il n’y a pas beaucoup d’argent à faire avec cette clientèle. Voyant la cible de l’AGI hors d’atteinte, OpenAI et les autres fournisseurs de GML misent donc sur une potentielle application-phare pour les entreprises. En entreprise, l’aide à la rédaction (idéation, traduction, résumé, correction, etc.) est utile mais concerne principalement des employés à bas salaire. Par contre, la programmation informatique est une activité susceptible d’intéresser les entreprises car elle concerne certains employés parmi les mieux rémunérés.
Cela dit, toutes les démos de codage avec GPT-5 que j’ai vues étaient pré-conçues et sentaient le réchauffé. Selon mes observations, et non une étude scientifique: Les gains de productivité spectaculaires grâce aux outils d’IA générative de programmation sont dus à de bons programmeurs, déjà plusieurs fois plus productifs que la moyenne. Les programmeurs moyens avec les outils d’IA générative atteignent parfois le niveau de bons programmeurs sans IA générative. Et le déboguage est un véritable problème, voire un cauchemar avec les outils d’IA générative. Les codeurs novices avec des outils d’IA générative sont capables de produire assez rapidement des logiciels qu’ils ne comprennent pas et qui sont fragiles. Pire encore, je pense que la plupart d’entre eux n’apprendront jamais à bien programmer et dépendront des outils d’IA générative toute leur vie. De plus, j’observe une érosion plus ou moins rapide des compétences en programmation due à l’abus des outils d’IA générative et à la loi du moindre effort.
En ajoutant le codage au ressenti (en anglais, vibe coding), nous risquons d’être confrontés à une dette technique explosive (mauvaise qualité du code). Ce problème existait déjà avec les méthodes agiles, lorsque les développeurs lésinaient sur les étapes de consolidation, de factorisation et de ré-architecture. On se retrouvera rapidement avec un château de cartes, ou encore un code spaghetti inextricable que ni l’IA générative ni les humains ne pourront maintenir.
Mais GPT-5 aurait fait une « découverte mathématique »
Le 20 août 2025, un billet sur X annonce que GPT-5 aurait prouvé un nouveau résultat en mathématique [20]. Plus précisément il s’agirait d’une preuve mathématique entièrement nouvelle qui établit une borne de 1,5/L en optimisation convexe. Les réseaux sociaux s’emballent et la nouvelle devient une « découverte mathématique » faite par GTP-5.
Cette allégation extraordinaire tombe à pic pour semer la confusion autour des réelles capacités de GPT-5. Mais la suspicion grandit quand on apprend que la nouvelle sur X émane d’un employé d’OpenAI.
Belle tentative, mais comme disait Carl Sagan, « Les allégations extraordinaires nécessitent des preuves extraordinaires». Rassurez-vous, il ne s’agit pas d’une grande découverte mathématique… L’allégation est outrancière car GPT-5 utilise des techniques de preuve bien connues (c’est-à-dire: divergence de Bregman, inégalités de lissage et de coercivité standard souvent utilisées en optimisation convexe) donc se retrouvant probablement en différents exemplaires dans les données d’entraînement du modèle.
Un robot conversationnel génératif (RCG) basé sur un GML, est fondamentalement un « traducteur » capable de prédire le prochain mot (en fait, un segment de texte ou jeton) dans une texte en tenant compte du contexte. Il ne raisonne pas et ne comprend rien en profondeur. Si les RCG donnent parfois l’impression de résoudre des problèmes mathématiques, c’est parce qu’ils maîtrisent le langage et la notation mathématique, puis ils trouvent des problèmes et des solutions par « recherche de motifs » dans leur espace latent en haute dimension qui a été créé par entraînement sur des corpus gigantesques incluant des milliers de preuves mathématiques, puis ils effectuent une recherche heuristique parmi de nombreuses solutions étape par étape. Ainsi, un RCG peut construire un fragment de preuve, voire une preuve pas trop éloignée de celles qui se trouvent dans son jeu de données d’entraînement, mais il ne s’agira probablement pas d’une grande « découverte mathématique ».
Tout au plus, nous avons là un résultat qui souligne le potentiel de l’IA pour assister le travail mathématique, mais aussi l’importance des experts humains dans l’énoncé des problèmes, leur mise en contexte et la validation des résultats de l’IA afin d’en déterminer la véritable nouveauté et la valeur.
Dans l’état de l’art actuel, une grande « découverte mathématique » par un robot conversationnel génératif n’est pas impossible, mais elle demeure très peu probable.
L’avenir est ailleurs
Désolé, mais la voie des GML a échoué. Pour atteindre le Graal d’une IA générale, il ne suffit pas de construire un modèle GML plus grand, il faudra remuer nos méninges naturelles…
Pour l’IA forte, les approches neurosymboliques comme celles proposées par François Chollet [21], Gary Marcus [22] et/ou causales qui intègrent des modèles explicites du monde, du genre architecture à vecteurs sémantiques joints (JEPA) de Yann LeCun [23] et les réseaux de flots génératifs (GFlowNet) de Yoshua Bengio [24] sont davantage porteurs.
Mais le GAFAM+ a très peu investi dans ces approches, préférant nous vendre du rêve.

Par Claude Coulombe
conseiller scientifique, DataFranca
Consulter l’article original
Notes et références
[1] GPT-4 est sorti le 14 mars 2023
[2] Un extrait vidéo de l’exposé de Kevin Scott, chef des technologies de Microsoft, à la journée Microsoft Build 2024, 21 mai 2024
[3] Traduction libre: « Nous sommes loin du point où la puissance des modèles d’IA que nous pouvons créer à mesure que nous augmentons l’échelle des calculs se mette à donner des rendements décroissants. »
[4] Traduction libre: « À mesure que les modèles gagnent en puissance, de nombreuses et nouvelles perspectives s’offriront à nous pour évoluer vers l’IA générale. »
[5] Déclaration de Sam Altman dans une vidéo de Tsarathustra (@tsarnick) sur X et rapporté sur Reddit, au début de 2025
[6] Déclaration de Sam Altman sur X en 2024
[7] Traduction libre: « L’humanité est proche de la création d’une superintelligence numérique. », déclaration de Sam Altman dans un billet de blogue intitulé « The Gentle Singularity », 10 juin 2025.
[8] GPT-5: Overdue, overhyped and underwhelming. And that’s not the worst of it, Gary Marcus, 09 août 2025.
[9] « GPT-5: Have We Finally Hit The AI Scaling Wall? », Sabine Hossenfelder, Youtube, 21 août 2025
[10] Traduction libre: Personne d’intellectuellement intègre ne devrait encore croire que la simple mise à l’échelle nous mènera à l’IA générale.
[11] Shojaee, P. & al. (2025). « The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity », Apple, juin 2025.
[12] Zhao, C. & al. (2025). « Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens », serveur de prépublication arXiv, 13 août 2025.
[13] Pour éviter l’anthropomorphisme, l’expression « chaîne de résolution » est proposée pour traduire « Chain of Thought » (CoT) plutôt que la traduction directe « chaîne de pensée ».
[14] Lindsey, J. & al (2025) « On the Biology of a Large Language Model», site transformer-circuits.pub, Anthropic, 27 mars 2025
[15] Coveney, P. V., & Succi, S. (2025). « The wall confronting large language models », serveur de prépublication arXiv, 30 juillet 2025
[16] « L’IA générative va-t-elle nous rendre stupides? », Claude COULOMBE, article LinkedIn, 21 novembre 2023.
[17] Stephanie Palazzolo, Erin Woo, Amir Efrati (2024)« OpenAI Shifts Strategy as Rate of ‘GPT’ AI Improvements Slows » – The Information, 09 novembre 2024
[18] C’est-à-dire, tous les textes de la Toile et les livres numériques sans égard aux droits d’auteur. Comme l’avouait « candidement » Elon Musk dans une entrevue en novembre 2023, tout part de l’emploi massif de toutes les données disponibles en format numérique, sans se soucier des droits d’auteur, pour entraîner des modèles d’IA. Les pirates corporatifs ont compris, qu’au pire ils se feraient épingler par la justice et devraient payer des sommes ridicules, après des années de recours et d’appels en justice.
[19] C’est un problème bien connu que beaucoup des données des bancs d’essais usuels sont divulguées (en anglais, leaked) sur la Toile. Dans les corpus gigantesques moissonnés sur la Toile, il est difficile de s’assurer qu’aucune réponse à des bancs d’essai ne retrouve dans les données d’entraînement.
[20] Message sur X de Sébastien Bubeck, employé d’OpenAI, 20 août 2025.
[21]« It’s Not About Scale, It’s About Abstraction », François Chollet, Youtube, 12 octobre 2024
[22] « How o3 and Grok 4 Accidentally Vindicated Neurosymbolic AI», Gary Marcus, blogue Marcus On AI, 13 juillet 2025
[23] « Yann Lecun: Meta AI, Open Source, Limits of LLMs, AGI & the Future of AI » – Lex Fridman Podcast #416 – 7 mars 2024
[24] « Are GFlowNets the future of AI? », Edward Hu, Youtube, 13 mars 2024